单链表
单链表指的是线性表的每个结点,分散地存储在内存空间中,向后依次用一个指针串联起来。
单链表的一般形式
不带表头结点

其中:data称为数据域,next称为指针域/链域;当head==NULL时,为空表;否则为非空表,表为一个非空表时,在首结点,*head中会存放数据。
带表头结点
非空表

空表
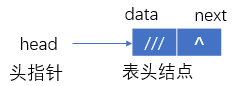
其中:head指向表头结点,head->data不放元素,head->next指向首结点$a_1$,当head->next==NULL时,为空表。
单链表的结点结构
1 | struct node |
生成单链表
例1:输入一列整数,以0为结束标志,生成“先进先出”单链表

这个单链表之所以称为先进先出单链表就是因为先进来的元素;通过变化表头指针可以先被删除。
首先定义结点空间所占大小,结点的数据域为整型数,然后定义指针域next。
1 |
|
每次输入元素后:
- 生产新结点:
p=malloc(结点大小); p->data=e; p->next=NULL; - 添加到表尾:
tail->next=p; - 设置新表尾:
tail=p;
生成“先进先出”单链表(链式队列)
1 | struct node *creat1() |
生成“先进后出”单链表(链式栈)

每次插入新元素后:
- 生成新结点:
p=malloc(结点大小); p->data=e; - 新结点指针指向原首结点:
p->next=head->next; - 新结点作为首元素:
head->next=p;
1 | struct node *creat2() |
插入一个结点
例1:在已知p指针指向的结点后插入一个元素x
首先用一个指针f指向新结点,该结点中的数据域为x,然后此新结点next域赋值为p指针指向结点的next域,最后p指针指向结点的next域赋值为f。
1 | f=(struct node *)malloc(LENG); //生成 |
例2:在已知p指针指向的结点前插入以一个元素x
因为单链表每个结点只有一个指针指向其后继结点,如果在结点前插入一个新结点,就需要得到指向p结点前驱结点的指针。
1 | f=(struct node *)malloc(LENG); |
单链表的算法
表头结点的作用
例:输入一列整数,以0为结束标志,生成递增有序单链表。

可以分为以下几种情况:
p、q同时空,意味着往空表中插入第一个结点;- 仅
p为空,q不为空,尾部插入,即数据插入到链表的尾部; - (仅
q为空)首部插入,即插入的数据作为单链表的第一个结点。
p、q可能为NULL
- (
p、q同时空)空表插入;f->next=p; - (仅
p为空)尾部插入;q->next=f; - (仅
q为空)首部插入;q不可能为空。
注意一点每次扫描已经存在的单链表确定数据插入的位置之前,做如下的初始化:
1 | struct node *creat3_1(struct node *head, int e) |
主函数算法
1 | main() |
生成带头结点的递增有序单链表(不包括0)
1 | void creat3_2(struct node *head, int e) |
主函数算法
1 | main() |
单链表的指定位置插入新元素
输入:头指针L、位置i、数据元素e
输出:成功返回OK,失败返回ERROR
计数如果在第i个位置上结束,p指向第i个位置,新元素就要插入到p指向的结点之前,我们之前分析过,如果插入到某个结点之前,就需要另一个复制指针q来指向p的前驱结点。

执行:p=L
当p不为空,执行p=p->next i-1次
定位到第i-1个结点
当i<1或p为空时插入点错
否则新结点加到p指向结点之后
1 | int insert(Linklist &L, int i, ElemType e) |
主要是三个大的部分:
- 扫描定位;
- 判断插入点位置为合法性;
- 在 p 指定的位置后面插入到新的结点。
在单链表中删除一个结点
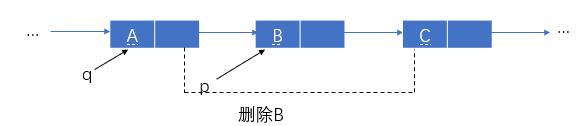
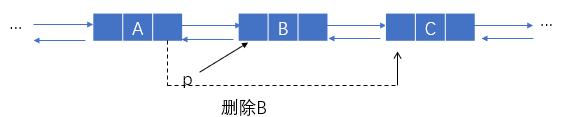
- 执行:
q->next=p->next; //A的next域=C的地址(B的next) - 执行:
free(p); //释放 p 所指向的结点空间
算法1:在带表头结点的单链表中删除元素值为e的结点
1 | int Delete1(Linklist head, ElemType e) |
算法2:在单链表中删除指定位置的元素

执行:p=L;
当p不为空,执行p=p->next i-1次,定位到第i-1个结点
当i<1时或p->next为空时删除点错,否则p指向后继结点的后继跳过原后继
1 | int Delete2(Linklist &L, int i, ElemType &e) |
单链表的合并
两个有序单链表的合并算法
将两个有序单链表La和Lb合并为有序单链表Lc;(该算法利用原单链表的结点)
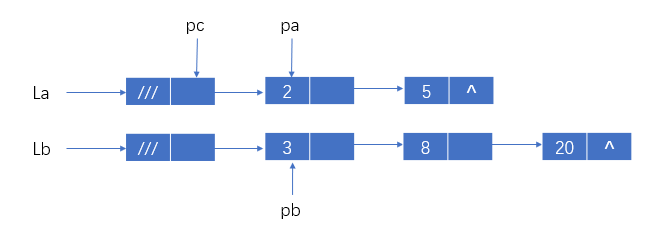
输入:两单链表的头指针
输出:合并后的单链表的头指针
1 | struct node *merge(struct node *La, struct node *Lb) |
循环链表
一般形式
带表头结点的非空循环单链表
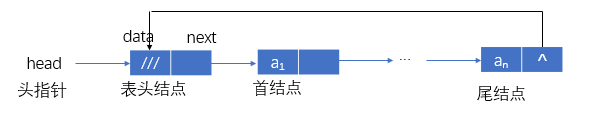
有:H->next≠H,H≠NULL。
带表头结点的空循环单链表
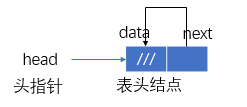
有:H->next≠H,H≠NULL。
只设尾指针的循环链表
非空表

有:tail指向表尾结点
tail->data=an
tail->next指向表头结点
tail->next->next指向首结点
tail->next->next->data=a1
空表
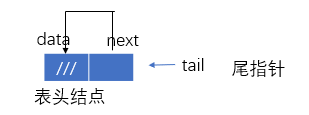
有:tail->next=tail
例:两循环链表首尾相连
如果是带头指针,时间复杂度$O(m+n)$
如果使用只设尾指针的循环链表
1 | p2=tail2->next; |
时间复杂度$O(1)$
循环链表算法举例
例:求以head为头指针的循环单链表的长度,并依次输出结点的值。
1 | int length(struct node *head) |
双向链表

1 | //结点类型定义 |
一般形式
非空表

有:L为头指针,L指向表头结点,L->next指向首结点
L->next->data=a1
L->prior指向尾结点,L->prior->data=an
L->next->prior=L->prior->next=NULL
空表

有:L->next=L->prior=NULL
双向循环链表
空表
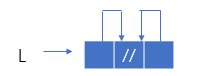
有:L->next=L->prior=L
非空表

设p指向a1,有:
p->next指向a2,p->next->prior指向a1
所以,p=p->next->prior
同理,p=p->prior->next
已知指针p指向结点B,删除B
1 | //执行 |
已知指针p指向结点C,在A,C之间插入B
1 | f->prior=p->prior; //结点B的prior指向结点A |